目录
- 一、关于SQL语句
- 1、子查询使用规则:
- 2、group by
- 3、多行子查询中包含group by
- 4、group by后面跟having
- 5、set verify on/off
- 6、define在sql语句的使用(类似于在script中定义)
- 7、关于ASSM(Automatic Segment Space Management)
- 8、关于intersect(交集)
- 9、系统用户登录数据库
- 10、关于non-equijoin
- 11、关于unlimited tablespace只能赋权给用户,不能给role;
- 12、alter system set x=?
- 13、关于distinct
- 14、关于动态性能视图
- 15、关于隐藏列(UNUSED)
- 16、关于虚拟列
- 17、单行子函数可以用在having()中
- 18、distinct 只能在select子句第一个位置使用,不能有两个 distinct 语句。
- 19、关于global temporary tables
- 20、关于DBLINK
- 21、关于UNUSED
- 22、修改列(有数据和无数据)
- 23、关于external tables和oracle_sql*load以及oracle_datadump
- 24、关于intersect的记忆点
- 25、关于Defer Segment Creation(延迟段创建的优点)
- 26、关于outer join
- 27、关于single row functions--常考
- 28、多行子查询、单行子查询、多列子查询
- 29、USING
- 二、关于数据迁移
- 1、数据迁移
- 三、关于SQL
- 四、使用 alter table tbname shrink space 来收缩表段
- 五、关于时间间隔数据类型
- 六、other
一、关于SQL语句
1、子查询使用规则:
子查询放在圆括号中
子查询放在比较条件右边(非强制)
子查询中不需要ORDER BY 子句
在单行子查询中使用单行运算符,在多行子查询中用多行运算符。
(1)单行运算符:子查询结果只有一个:< > = <= >= !=
SQL> select employee_id,last_name,job_id,salary from employees where salary<(select salary from employees where job_id='IT_PROG' and salary>8000);
(2)多行子查询:子查询结果是单列多行:in , any,all,exists,not exists
SQL> select employee_id,last_name,job_id,salary from employees where salary<ALL(select salary from employees where job_id='IT_PROG') AND job_id<>'IT_PROG';
(3)多列子查询:子查询为多列,一定要在FROM后作为表,且一定要取别名,否则无法访问这张表中的字段。
SQL> select employee_id,last_name,job_id,em.salary,test.salary from employees em,(select salary from employees where job_id='IT_PROG') test;
2、group by
SQL> select avg(salary),job_id from employees group by job_id;
3、多行子查询中包含group by
SQL> select employee_id,last_name,job_id,salary from employees where job_id in(select job_id from employees where salary>8000 group by job_id);
4、group by后面跟having
HAVING子句可以让我们筛选分组后的各组数据,WHERE子句在聚合前线筛选记录,也就是说作用在GROUP BY 子句和HAVING子句前 而HAVING子句在聚合后对组记录进行筛选。 HAVING子句可针对汇总运算得到的结果进行筛选,取得聚合特征符合某一条件的数据集,
SQL> select employee_id,last_name,job_id,salary from employees where job_id in(select job_id from employees where salary>8000 group by job_id having(job_id='AD_VP'));
5、set verify on/off
当在sqlplus中运行的sql语句中有替代变量(以&或&&打头)的时候,
set verify(或ver) on:显示替代变量被替代前后的语句。
set verify(或ver) off:不显示替代变量被替代前后的语句。
如: SQL> set ver on; SQL> select * from dual where 1=&var; Enter value for var: 1 old 1: select * from dual where 1=&var new 1: select * from dual where 1=1 而如果设为off,则显示如下: SQL> set ver off; SQL> select * from dual where 1=&var; Enter value for var: 1
6、define在sql语句的使用(类似于在script中定义)
定义了变量1,则在执行select时,不需要手动输入
SQL> define 1='17-JUN-03'; SQL> SELECT employee_id, first_name, salary FROM employees WHERE hire_date >'&1';
7、关于ASSM(Automatic Segment Space Management)
ASSM 管理的表空间在 insert 操作的时候总是找一个块能够放下整行的数据。基
本压缩和高级压缩的段默认的 pctfree 都是 10%,其它的 hcc 压缩方式的段无法测试
8、关于intersect(交集)
用于两张表或多张表进行交集
条件:
两张表的列数量必须一致 ,两张表的列名称可以不一样(展示第一个表的列名) ,两张表的列的数据类型必须要一致
SQL> select * from test_3 intersect select * from test_7; SQL> select * from test_3 intersect select * from test_7 intersect select * from test_5;
INTERSECT 不会忽略空值。
为了符合新出现的 SQL 标准,Oracle 的未来版本将赋予 INTERSECT 运算符比其他 set 运算符更高的优先级。
因此,在使用 INTERSECT 运算符和其他集合运算符的查询中, 应该使用括号来指定求值顺序。
INTERSECT 不会忽略空值。)
9、系统用户登录数据库
将用户设置为extenally模式:alter user test to be identified externally;
10、关于non-equijoin
(1)The join syntax used makes no difference to performance; (2)Table aliases can improve performance (3)The SQL:1999 compliant ANSI join syntax supports creation of a Cartesian product of two tables. (4)The Oracle join syntax supports creation of a Cartesian product of two tables. (5)The Oracle join syntax performs better than the SQL:1999 compliant ANSI join syntax (此选项好像是不对的)
11、关于unlimited tablespace只能赋权给用户,不能给role;
12、alter system set x=?
指示这个参数的作用域,默认是both。
SCOPE=memory 只在当前实例中修改,数据库重启后恢复成原先的值。
SCOPE=spfile 只修改spfile中的值,这个值直到数据库重启后才生效。
SCOPE=both 内存和spfile中都修改参数的值。
13、关于distinct
如果加了 distinct,则出现排序的列必须是在 select 子句中出现,
如果是表达式,则用表达式排序。
SQL> select distinct(ID*5) as test from test_3 order by test; SQL> select distinct(ID*5) as test from test_3 order by ID*5;
14、关于动态性能视图
动态性能视图的内容是来源于内存与控制文件,在 mount 状态下可以访问所以的视图,由于不断的更新,所以不保证读一致性,这个是经典的答案。
15、关于隐藏列(UNUSED)
不能把表的所有列设置为 unused;可以同时设置多个列 unused。
列一旦被设置为 unused 以后,基于该列的约束、索引都被删除,同时相关的视图被无法访问。经过实验,可以马上往该表添加名字一样的列。)
-
.在oracle中 unused的作用主要是隐藏列,如下图以 ce表为列

2.unused的语法也比较简单
unused(字段1,字段2....);

3.再次查询的时候发现address列已经不存在了,与图1相比缺少了address列

4.对于隐藏的列我们可以通过如下方式进行查看。对于隐藏的列是不可以进行恢复操作的,只能查看和删除。
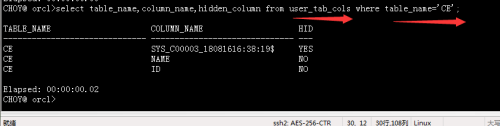
5.它的应用不仅仅是隐藏列,对于大数据表的处理通常在做删除列的时候由于数据量非常大,所以在删除的时候无法直接删除而采用先隐藏的方式,然后在空闲的时候再删除。通过下图方式可以删除隐藏列

6.删除隐藏列后,再查看隐藏列发现已经被删除,不存在了。

16、关于虚拟列
(1)可以为虚拟列创建索引(Oracle为其创建function index)
(2)可以搜集虚拟列的统计信息statistics,为CBO提供一定的采样分析。
(3)在update或delete语句中,可以在where 后面使用虚拟列作为选择条件(
(4)只在一处定义,不存储多余数据,查询是动态生成。
(5)注意不能直接插入或修改虚拟列的值。
你可以定义虚拟列的数据类型,如果不指定,oracle会自动指定为定义中依赖的列的数据类型。
注意事项
(1) 只有堆组织表(heap-organized table)才可以定义虚拟列
(2) 虚拟列不能引用其他的虚拟列
(3) 虚拟列只能引用自己表中的列, 不能引用其他表中的列。
(4) 虚拟列值只能是标量 scalar value (a single value, not a set of values)
17、单行子函数可以用在having()中
SQL>SELECTprod_id FROM sales WHERE quantity_sold>55000 GROUR BY prod_id HAVING COUNT(*)>10;
18、distinct 只能在select子句第一个位置使用,不能有两个 distinct 语句。
19、关于global temporary tables
有关临时表的考点出现比较多。不管是基于那种级别,临时表是不会因为会话结束而被删除,数据会被删除,但是保留表结构。以下是临时表的特点:
(1)创建 SQL 语句
CREATE GLOBAL TEMPORARY TABLE tablename (columns) [ ON COMMIT PRESERVE | DELETE ROWS ]
事务级别,此为默认选项
SQL> create global temporary table emp_temp(eno number) on commit delete rows; -- transaction level duration,
会话级别
SQL> create global temporary table emp_temp(eno number) on commit preserve rows; --session level duration,
(2)隔离性:
数据只在会话或者事务级别可见。不同用户可以使用同一个临时表,但是看到的都是各自的数据。
(3) 表上可以创建索引、视图、触发器等对象。
(4) 索引只有在临时表是 empty 时可创建。
(5) 临时表不产生数据的 redo,但是会生成 undo 的 redo。
(6) 临时表目前只支持 GLOBAL 的,所以创建语句为 create global temporary table XXX。
(7) 使用 truncate 只对当前会话有效。
(8) 不能 export/import 表上的数据,只能导入导出表定义。
(9)临时段在第一次 insert 或 CATS 时产生
(10)不能创建外键
20、关于DBLINK
一个 DBLINK 只能在两个数据库之间创建
21、关于UNUSED
列一旦被设置为 unused 以后,基于该列的约束、索引都被删除,
同时相关的视图被无法访问,
但是列的数据需要 drop column 时才会被删除
22、修改列(有数据和无数据)
在oracle中,如果列中无数据,可以直接进行修改:
(1)修改列名定义
alter table test modify id number(10);
(2)删除列
ALTER TABLE test DROP COLUMN id;
(3)重命名列
SQL>ALTER TABLE test RENAME COLUMN ID TO ID_2;
人直接在表结构设计这里修改,这里只适合修改列没有数据,可修改
(4)修改表名
SQL>rename test to test2;
23、关于external tables和oracle_sql*load以及oracle_datadump
(1)The ORACLE_DATAPUMP access driver can be used to unload data from a database into an external table. (2)External table files can be used for other external tables in a different database. (3)The ORACLE_LOADER access driver can be used to load data from an external table into a database
24、关于intersect的记忆点
除了numbers of columns必须要identical,names of columns不需要相同;
it not ignores null values;
25、关于Defer Segment Creation(延迟段创建的优点)
(1)table 和index默认的行为
It is the default behavior for tables and indexes.
(2)index是延迟还是立即,是继承父表(inherit)特性
Indexes inherit the DEFERRED or IMMEDIATE segment creation attribute from their parent table.
(3)它支持包含在本地管理的表空间中的索引组织表(IOT)。
It is supported for Index Organized Tables (IOTs) contained in locally managed tablespaces.
26、关于outer join
(left outer join或left join,right outer join或right join,full join或full right join)
outer join 支持2表或多表查询(3,4张表都OK) SQL> select * from test_3 a left outer join test_5 b on a.name=b.name and a.id=b.id left join test_4 c on c.id=a.id;
27、关于single row functions--常考
A . MOD : returns the remainder of a division operation.
B . TRUNC : can be used with NUMBER and DATE values.
C . CONCAT : joins two character strings together连接两个字符串(不能是任意数量)
D . SYSDATE : returns the database server current date and time.
E . INSTR : 查找下标元素,可以是第一次或第多次出现的位置
F . TRIM : can be used to remove the spaces at the beginning and end of the string (去掉首尾空格)
G. CEIL: can be used for positive and negative numbers. (向上取整,正负数都支持)
returns the smallest integer greater than or equal to a specified number
H. FLOOR: returns the largest integer less than or equal to a specified number.(向下取整,正负数都支持)
28、多行子查询、单行子查询、多列子查询
(1)单行子查询
单行子查询的select语句只返回一行数据,也就是说嵌入在其他Sql语句中的那个select查询值返回一行数据。
select * from emp where deptno=(select deptno from emp where ENAME='SMITH');--这里的select查询只返回一行数据
(2)多行子查询
多行子查询就是嵌入在其他Sql语句中的select查询返回多行数据。
子查询结果只能用in,all,any等。
select * from emp where job = (select distinct job from emp where deptno=10) --这里的select查询返回多行记录
(3)单列子查询
使用多列子查询来解决这个问题
select * from emp where (deptno,job)=(select deptno,job from emp where ename='SMITH') --列的顺序一定要相同
29、USING
需要有等值连接或using方法
注:内连接的 using 用法,using 只能用在 equiue join ,而且必须列的名字要 相同,类型可以不同,但是可以隐式转过去
二、关于数据迁移
1、数据迁移
(12C及后,可以不用mount迁移数据文件或在线offline,直接使用resuse在线就可以实现)
SQL> alter database move datafile '/oracle/oradata/test_del.dbf' to '/oracle/oradata/test_2.dbf' reuse;
三、关于SQL
1、union和union all的区别
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
union和union all的区别是,union会自动压缩多个结果集合中的重复结果,而union all则将所有的结果全部显示出来,不管是不是重复。Union All 速度比Union快。
2、时间/日期函数
(1)Oracle中的时间类型只有date和TIMESTAMP,TIMESTAMP是比date更精确的类型。
日期时间函数用于处理时间类型的数据,Oracle以7位数字格式来存放日期数据,包括世纪、年、月、日、小时、分钟、秒,并且默认日期显式格式为“DD-MON-YY”。
在Oracle中准确来说一个礼拜是从星期日开始到星期六结束的,其中时间差以天数为单位。
SYSDATE:取得当前的日期和时间,类型是DATE.它没有参数.但在分布式SQL语句中使用时,SYSDATE返回本地数据库的日期和时间.
SYSTIMESTAMP:9i新增函数,返回当前系统的日期时间及时区。
(2)多种日期格式:
YYYY:四位表示的年份 YYY,YY,Y: 年份的最后三位、两位或一位,缺省为当前世纪 IYYY: ISO标准的四位年份 MM: 01~12的月份编号 MON: 缩写字符集表示 MONTH: 全拼字符集表示的月份,右边用空格填补 Q: 季度 W: 当月第几周 WW: 当年第几周 IW: ISO标准的年中的第几周 D: 当周第几天 DD: 当月第几天 DDD: 当年第几天 DY: 缩写字符集表示 DAY: 全拼字符集表示的天 如(星期六) HH,HH12: 一天中的第几个小时,12进制表示法 HH24: 一天中的第几个小时,取值为00~23 MI: 一小时中的分钟 SS: 一分钟中的秒 SSSS: 从午夜开始过去的秒数
(3)细讲+
col DBTIMEZONE for a10 col SESSIONTIMEZONE for a10 col LOCALTIMESTAMP for a30 col CURRENT_TIMESTAMP for a40 col SYSTIMESTAMP for a40 set line 300
SQL> select sysdate,DBTIMEZONE,SESSIONTIMEZONE,LOCALTIMESTAMP,CURRENT_TIMESTAMP,SYSTIMESTAMP from dual; SYSDATE DBTIMEZONE SESSIONTIM LOCALTIMESTAMP CURRENT_TIMESTAMP SYSTIMESTAMP -------------------- ---------- ---------- ------------------------------ ----------------------------------- ----------------------------------- 02-AUG-2022 09:35:33 +08:00 +08:00 02-AUG-22 09.35.33.219840 AM 02-AUG-22 09.35.33.219840 AM +08:00 02-AUG-22 09.35.33.219838 AM +08:00
 TIMEZONE:指的是当地时间与本初子午线英格兰格林威治时间的时差
TIMEZONE:指的是当地时间与本初子午线英格兰格林威治时间的时差
北京是东八区(+08:00),即北京时间-格林威治=8小时,北京比格林威治早8小时看到太阳
DBTIMEZONE:返回数据库时区.
DBTIMEZONE returns the value of the database time zone
SESSIONTIMEZONE:返回当前会话时区
SESSIONTIMEZONE returns the time zone of the current session
LOCALTIMESTAMP:返回session端不带时区的timestamp格式的当前时间
LOCALTIMESTAMP returns the current date and time in the session time zone in a value of data type TIMESTAMP
CURRENT_TIMESTAMP:返回session端带时区的timestamp格式的当前时间
CURRENT_TIMESTAMP returns the current date and time in the session time zone, in a value of data type TIMESTAMP WITH TIME ZONE.
SYSTIMESTAMP:返回带时区的timestamp格式的当前数据库时间
SYSTIMESTAMP returns the system date, including fractional seconds and time zone, of the system on which the database resides. The return type is TIMESTAMP WITH TIME ZONE.
3、Oracle中nvl()与nvl2()函数详解:
函数nvl(expression1,expression2)根据参数1是否为null返回参数1或参数2的值;
若expression1值为null,则该函数返回expression2; 若expression1值不为null,则该函数返回expression1; 若expression1、expression2的值均为null,则该函数返回null。
函数nvl2(expression1,expression2,expression3)根据参数1是否为null返回参数2或参数3的值。
若expression1值不为null,则该函数返回expression2值; 若expression1值为null,则该函数返回expression3值; 若expression1、expression2、expression3值均为null,则该函数返回null。
4、关于joins(outer joins/inner joins)
inner join返回是匹配的rows
out join返回的是匹配和不匹配的rows
out joins可以有多个join conditions
四、使用 alter table tbname shrink space 来收缩表段
两个参数:alter table tbname shrink cascade/compact
cascade:缩小表及其索引,并移动高水位线,释放空间
compact:仅仅是缩小表和索引,并不移动高水位线,不释放空间,后面单独进行alter table tbname shrink space (相当于带cascade参数)
ALTER TABLE <table_name> ENABLE ROW MOVEMENT -->前提条件 ALTER TABLE <table_name> SHRINK SPACE [ <NULL> | COMPACT | CASCADE ]; ALTER TABLE <table_name> SHRINK SPACE COMPCAT; -->缩小表和索引,不移动高水位线,不释放空间 ALTER TABLE <table_name> SHRINK SPACE; -->收缩表,降低高水位线; ALTER TABLE <table_name> SHRINK SPACE CASCADE; -->收缩表,降低高水位线,并且相关索引也要收缩一下 ALTER TABLE <table_name> MODIFY LOB (lob_column) (SHRINK SPACE); -->收缩LOB段 ALTER INDEX IDXNAME SHRINK SPACE; -->索引段的收缩,同表段
五、关于时间间隔数据类型
interval:时间间隔数据类型,有INTERVAL YEAR TO MONTH和INTERVAL DAY TO SECOND两种类型。
1、 INTERVAL YEAR TO MONTH
使用该数据类型来保存以月为精度的时间间隔信息
语法:INTERVAL YEAR(percision) TO MONTH;
percision的取值范围为0-4.默认是2
2、INTERVAL DAR TO SECOND
使用该数据类型来保存以秒为精度的时间间隔信息
语法:INTERVAL DAY[(leading_precision)]TO SECOND[(fractional_seconds_precision)];
leading_precision和fractional_seconds_precision的取值范围是0-9.
默认情况下leading_precision是2,fractional_seconds_precision是6。
含义和INTERVAL YEAR TO MONTH类似。
六、other
1、Automatic Workload Repository (AWR)
Automatic Workload Repository (AWR) snapshots 存储在sysaux表空间中。
2、关于行迁移和行链接
行链接会导致一行存放在多个数据块中;一行的多个片段可以存放在同一个块中也可能存放在不同的数据块中。我们用 bbed 工具实验发现,我们修改一行中的某个列值,如果长度大于原来的列,则该列值会放在同一个块的 free 空间中,如果 free 空间不够,则发生行迁移,如果一个块的空间放不下一行的数据,则发生行链接。这道题考的深度很深。

